
How good is Mythos?
Is Claude Mythos Preview a particularly big jump in AI capabilities?

Last month, Anthropic announced a new model, Claude Mythos Preview. They decided not to make it generally available due to its “large increase in capabilities,” instead only releasing it for a limited set of partners as part of a defensive cybersecurity program. The model’s capabilities, especially in cyber, received substantial attention, including claims that it’s “a particularly big jump” and that it shows that AI progress is potentially speeding up.
In this post I attempt to answer: is it a particularly big jump in capabilities? Does it demonstrate that AI progress is speeding up? Or is it roughly what we expect from recent AI progress? And how long will it take for its capabilities to be generally available in the market?
To answer this, I will exclusively use publicly available, quantitative data on how Mythos Preview compares to publicly released models.
I find that across cyber capabilities evaluations, Mythos Preview appears similar to what you’d expect from recent AI progress, or slightly ahead by a few weeks. It’s essentially tied with GPT 5.5 on all comparable cyber evaluations, both “narrow” and “broad.” On many high-quality benchmarks, Mythos Preview appears to be ahead by a month or two on average. Mythos Preview’s forte is SWE-bench Pro, where it’s roughly three months ahead of the trend line, though with meaningful uncertainty and concerns with possible memorization.
Cyber capabilities
Let’s start by examining Mythos Preview’s cyber capabilities, as that is what the model is most known for. Mythos Preview’s system card does not have much information that allows us to quantitatively compare it with publicly available models on cyber capabilities. So instead, we’ll turn to blog posts from the United Kingdom’s AI Security Institute (UK AISI) and Microsoft, who evaluated the model, for this information.
The UK AISI evaluations
The UK AISI separates its evaluations into two types, “narrow” and “broad” cyber capabilities. Let’s look at each category individually.
“Narrow” challenges
“Narrow” challenges follow the capture-the-flag (CTF) format, and span four difficulty tiers, from easier tasks that “have a small to moderate search space and require only a few steps to solve fully” to much harder challenges “with a significantly larger and more complex search space, as well as more overall steps required to solve.”
The easiest tier (technical non-expert) has been saturated long ago, so it’s uninteresting. For the other tiers, here is how Mythos Preview (and GPT 5.5, when the data is available) perform compared to the pre-Mythos Preview trend line:1
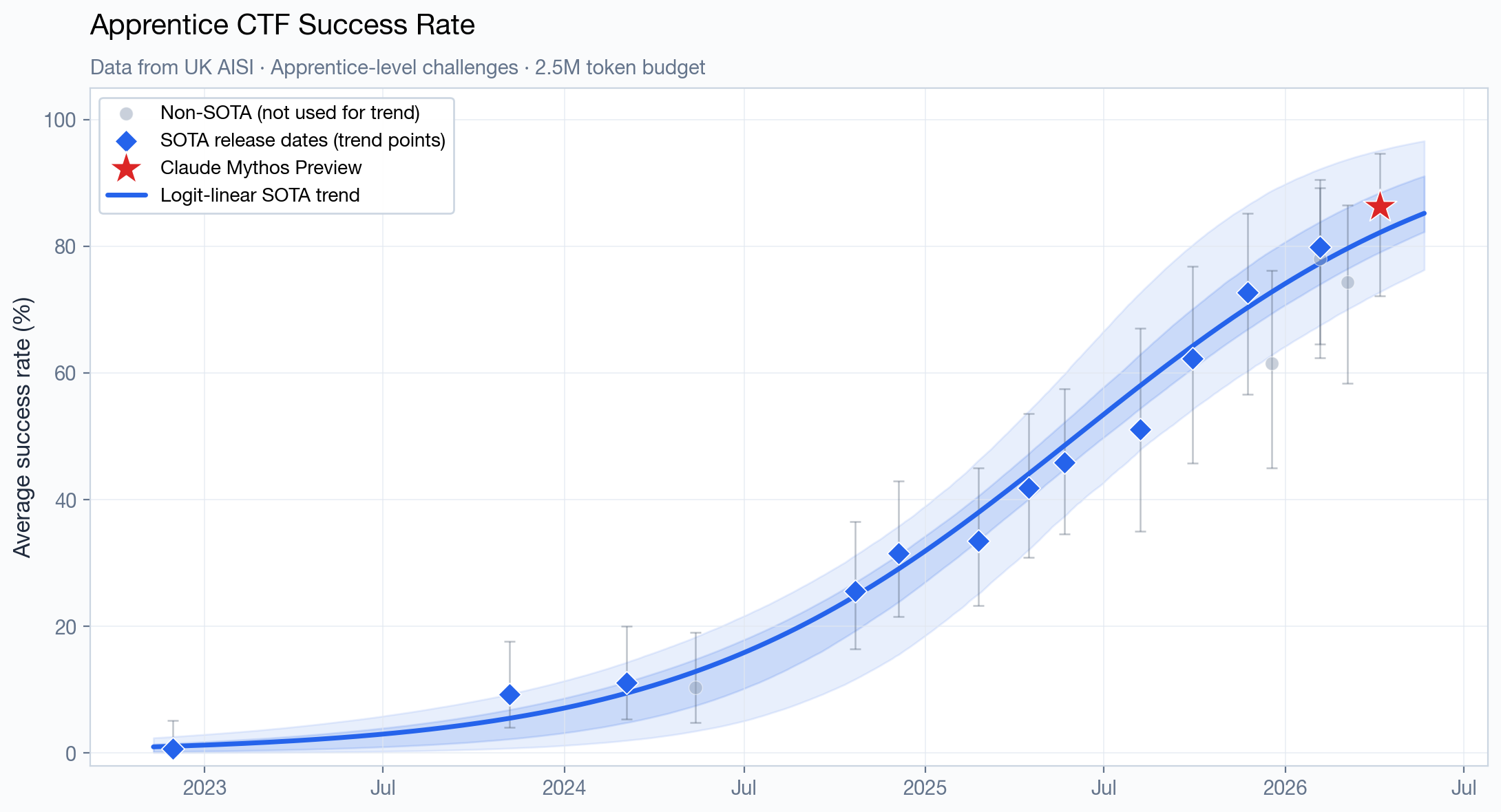
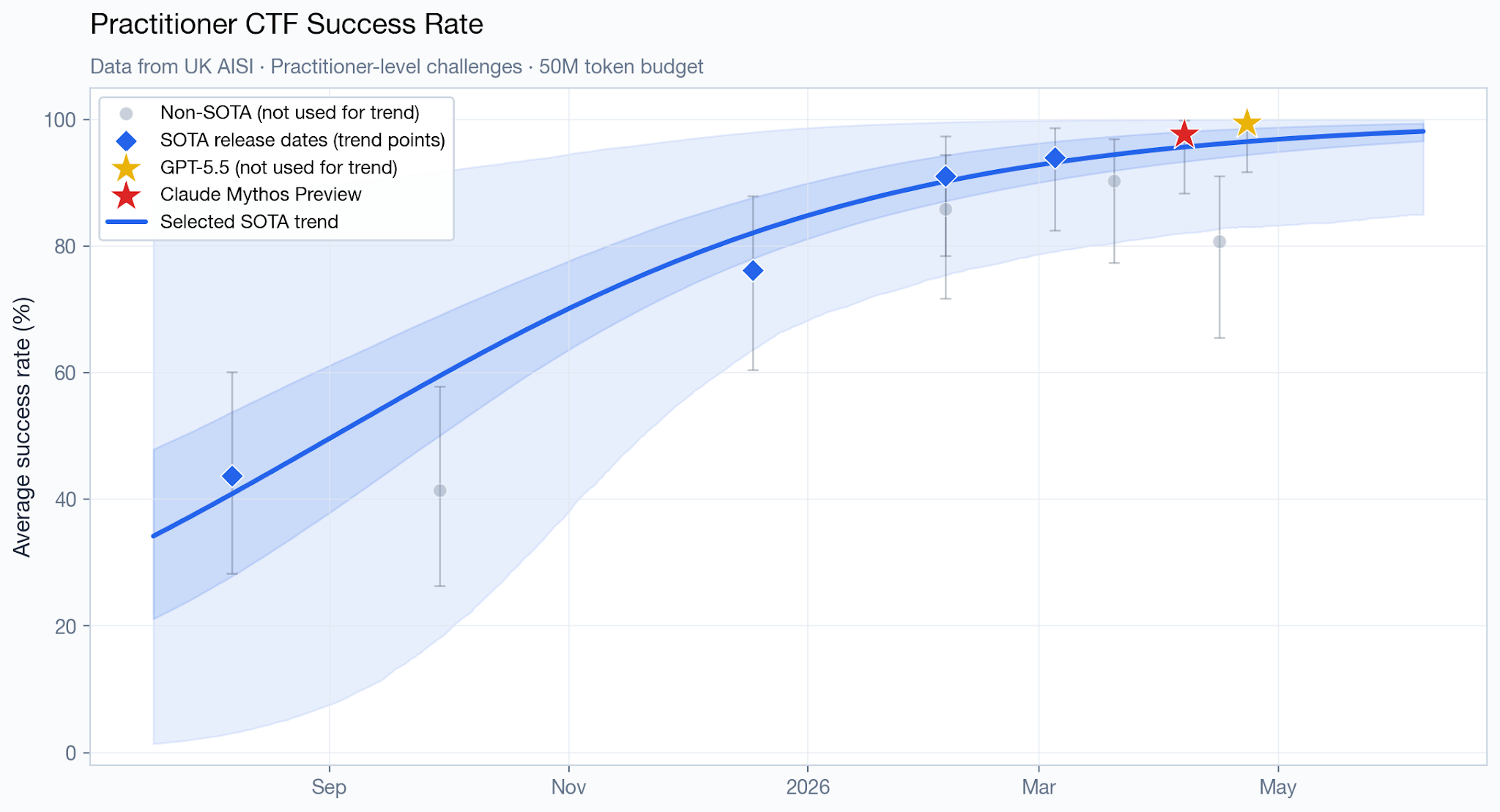
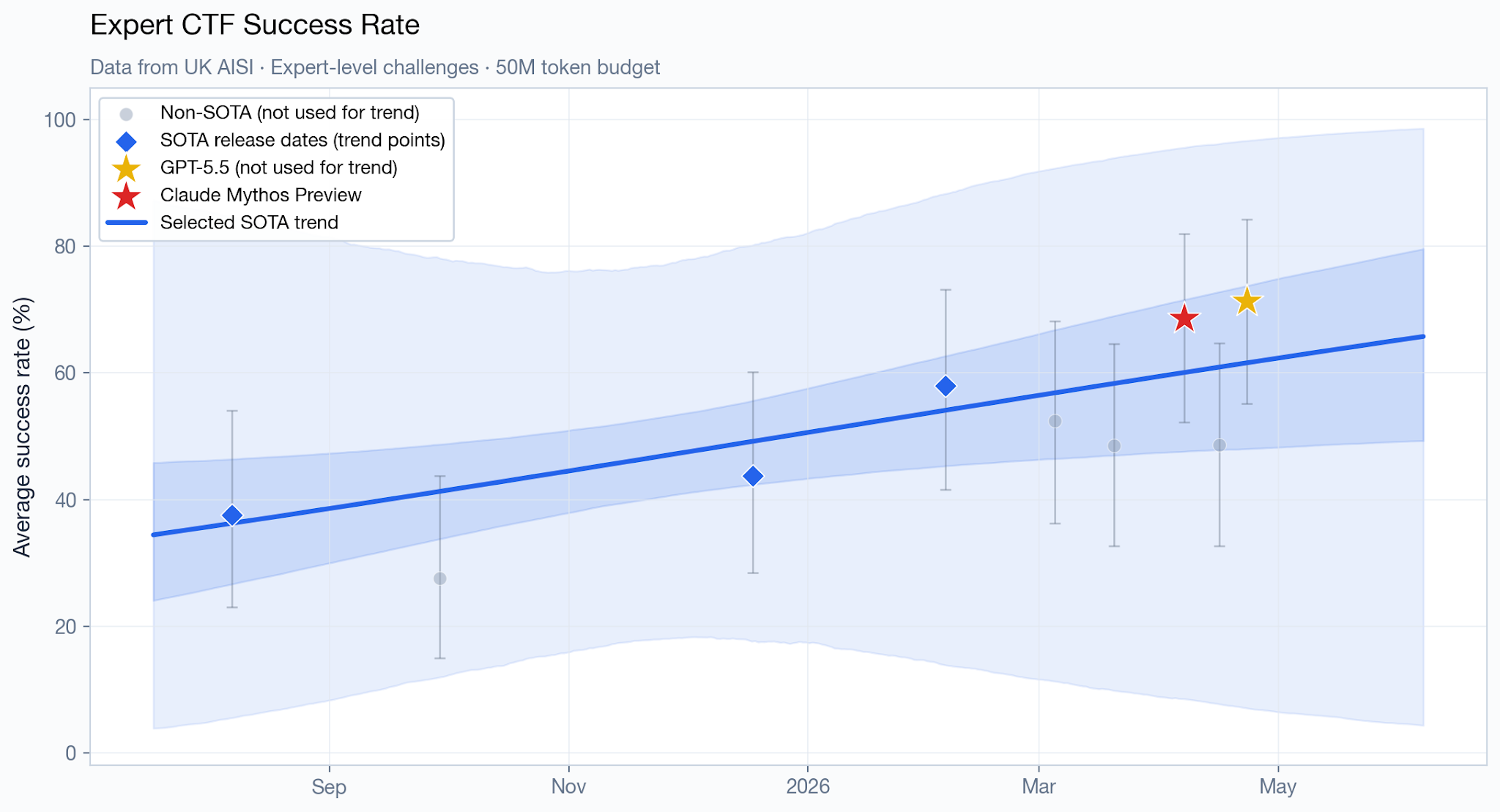
It’s hard to tell with only a handful of datapoints, but Mythos Preview and/or GPT 5.5 appear to be directionally ahead of the trend on some of those charts. However, there’s wide uncertainty, the magnitude is relatively small (roughly two months ahead at the point estimate) and the data is consistent with both being exactly on-trend, or several months ahead.
“Broad” challenges (cyber ranges)
As the UK AISI puts it, “[e]ven expert-level CTFs only test specific skills in isolation. Real-world cyber-attacks require chaining dozens of steps together across multiple hosts and network segments — sustained operations that take human experts many hours, days, or weeks to complete.”
So they also have tests estimating broad cyber capabilities, which they call “cyber ranges.” The UK AISI evaluated Mythos Preview and GPT 5.5 on a cyber range test called “The Last Ones” (TLO).
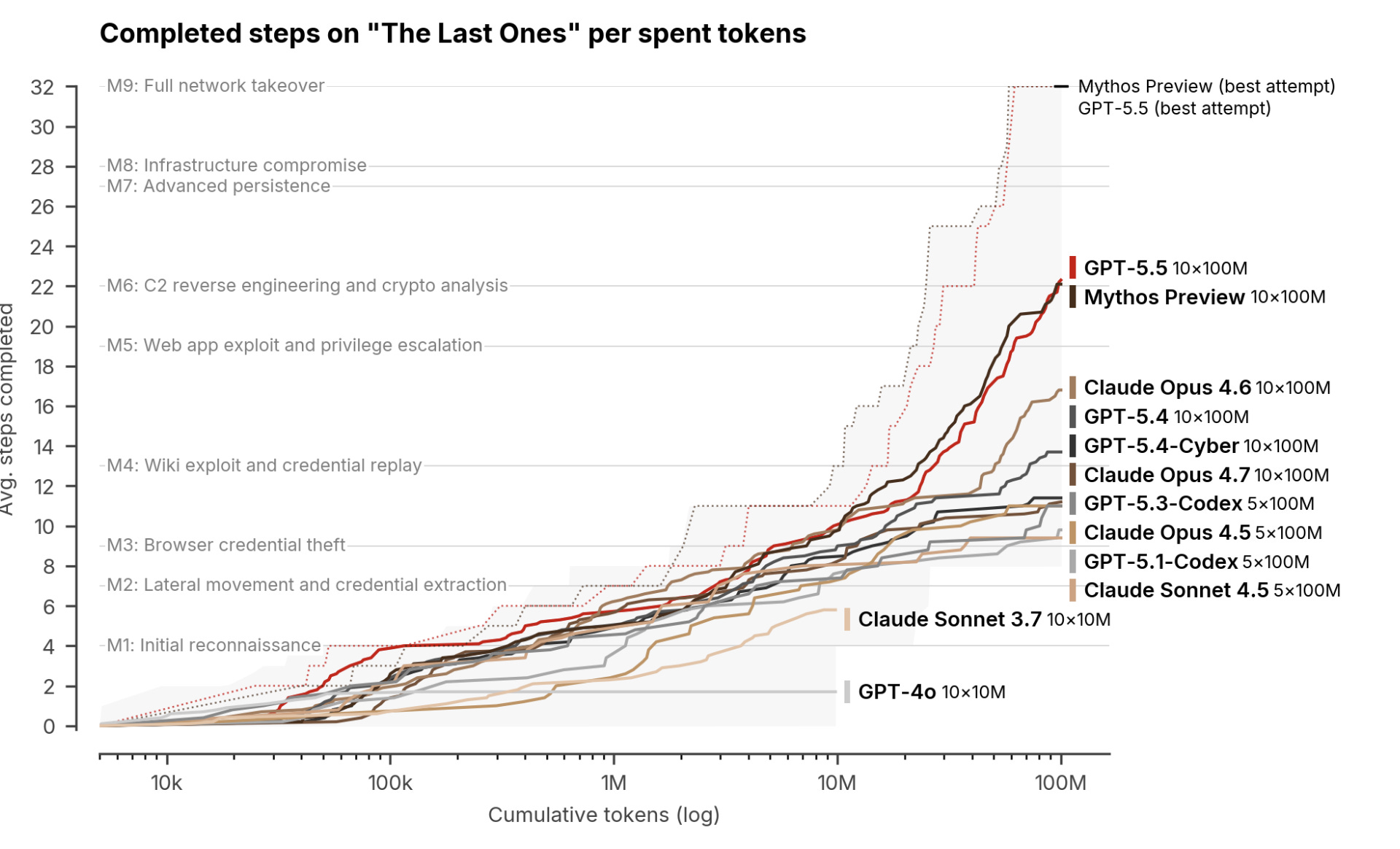
Mythos Preview was the first model to complete the TLO cyber range – ie, complete all 32 steps in at least one of the 10 attempts. As Anthropic said in the system card:
Claude Mythos Preview is the first model to solve one of these private cyber ranges end-to-end. These cyber ranges are built to feature the kinds of security weaknesses frequently found in real-world deployments, including outdated software, configuration errors, and reused credentials. […]
Claude Mythos Preview solved a corporate network attack simulation estimated to take an expert over 10 hours. No other frontier model had previously completed this cyber range.
This sounds really impressive, but, importantly, it does not appear to imply a large jump in capabilities. When we look at the data, we see that Opus 4.6 was already very close to completing the cyber range: in its best attempt out of 10, it completed 28 out of the 32 steps.
For this metric, we cannot estimate a trend line: most of the older datapoints are not comparable (they use fewer attempts and/or tokens), so I created a datapoint-only chart.
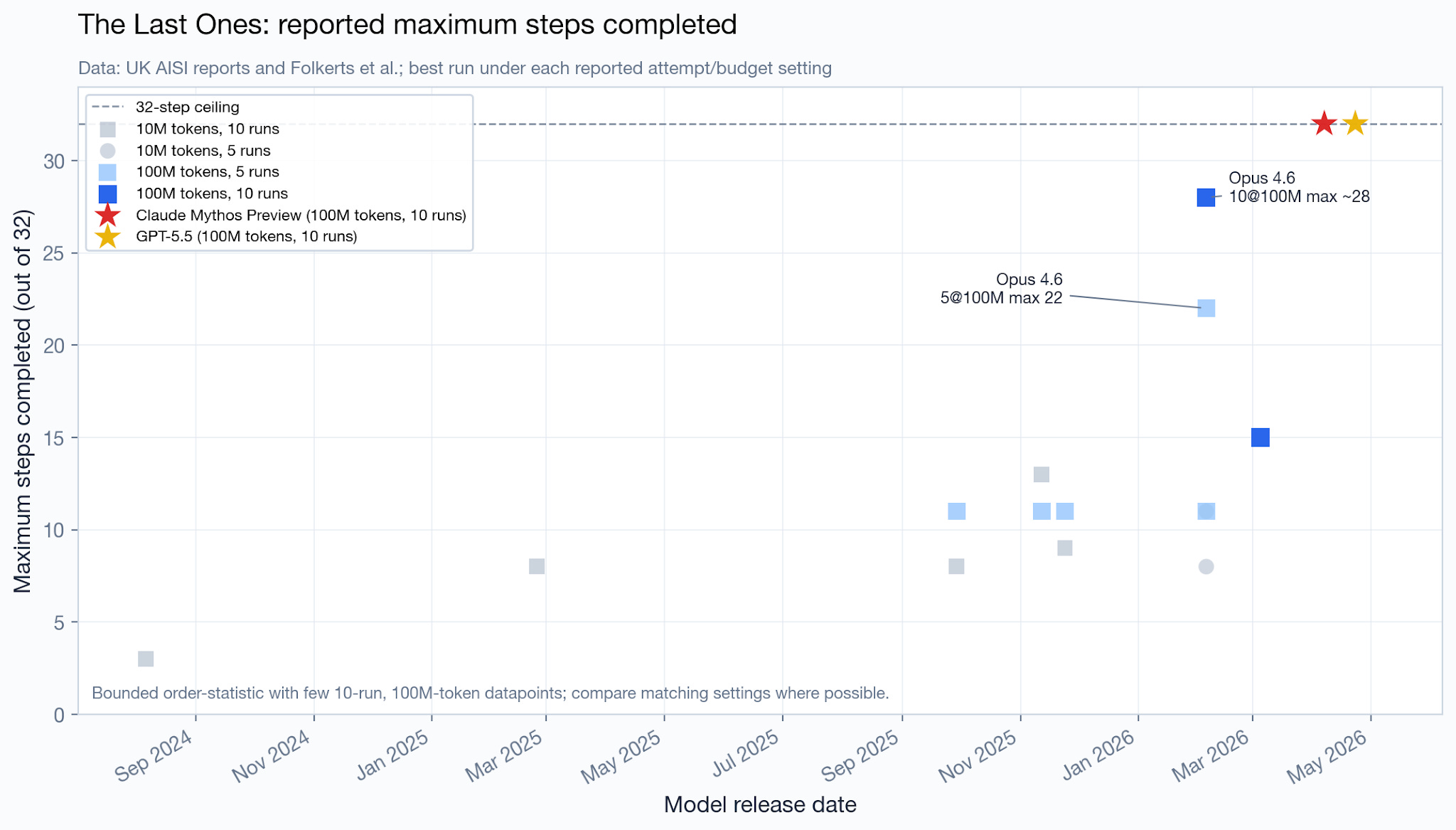
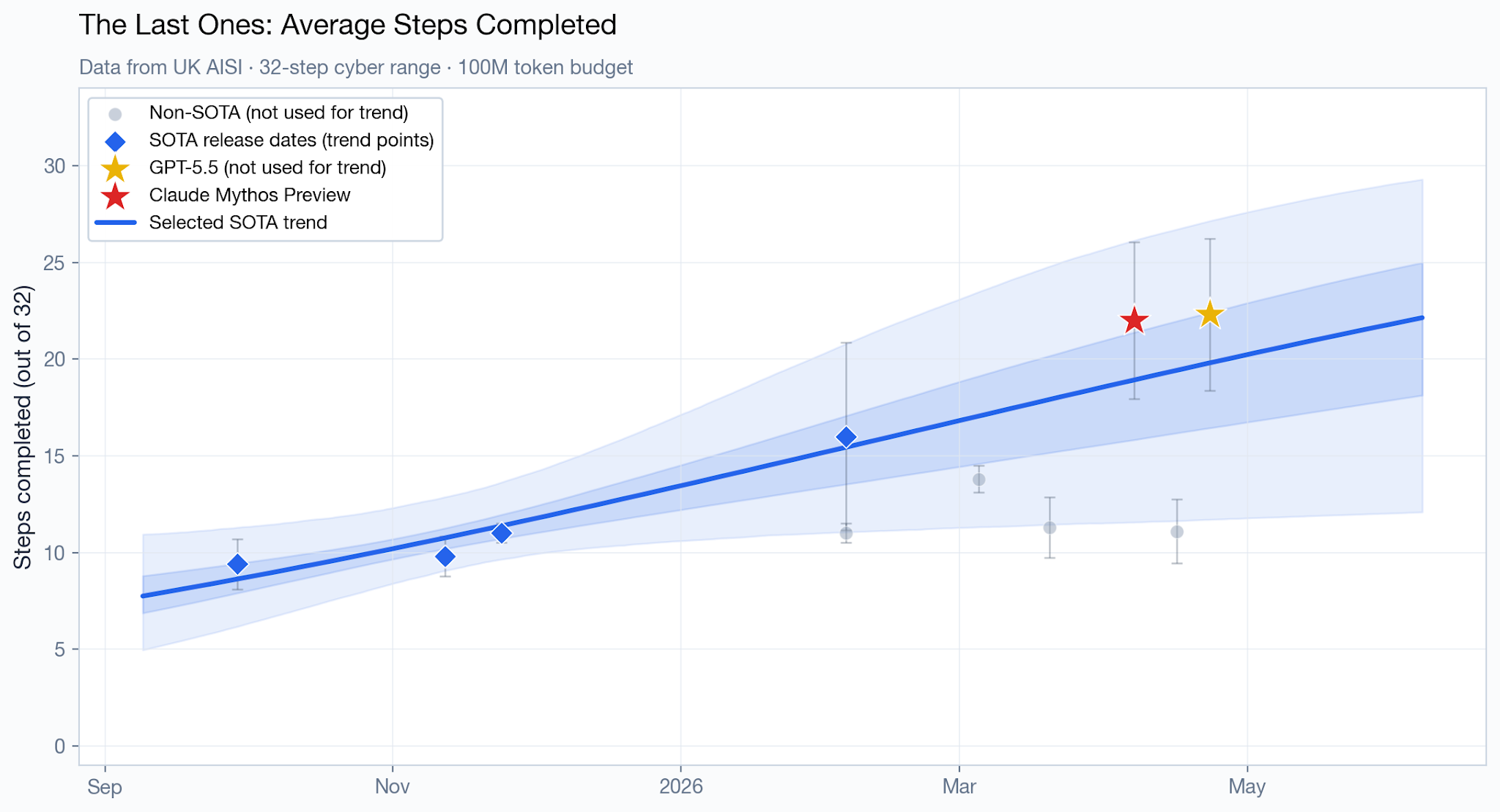
In terms of average number of steps completed in this cyber range, Mythos Preview appears to be, directionally, slightly ahead of the trend line, though we only have a handful of datapoints to extrapolate from. GPT 5.5 is almost exactly tied.
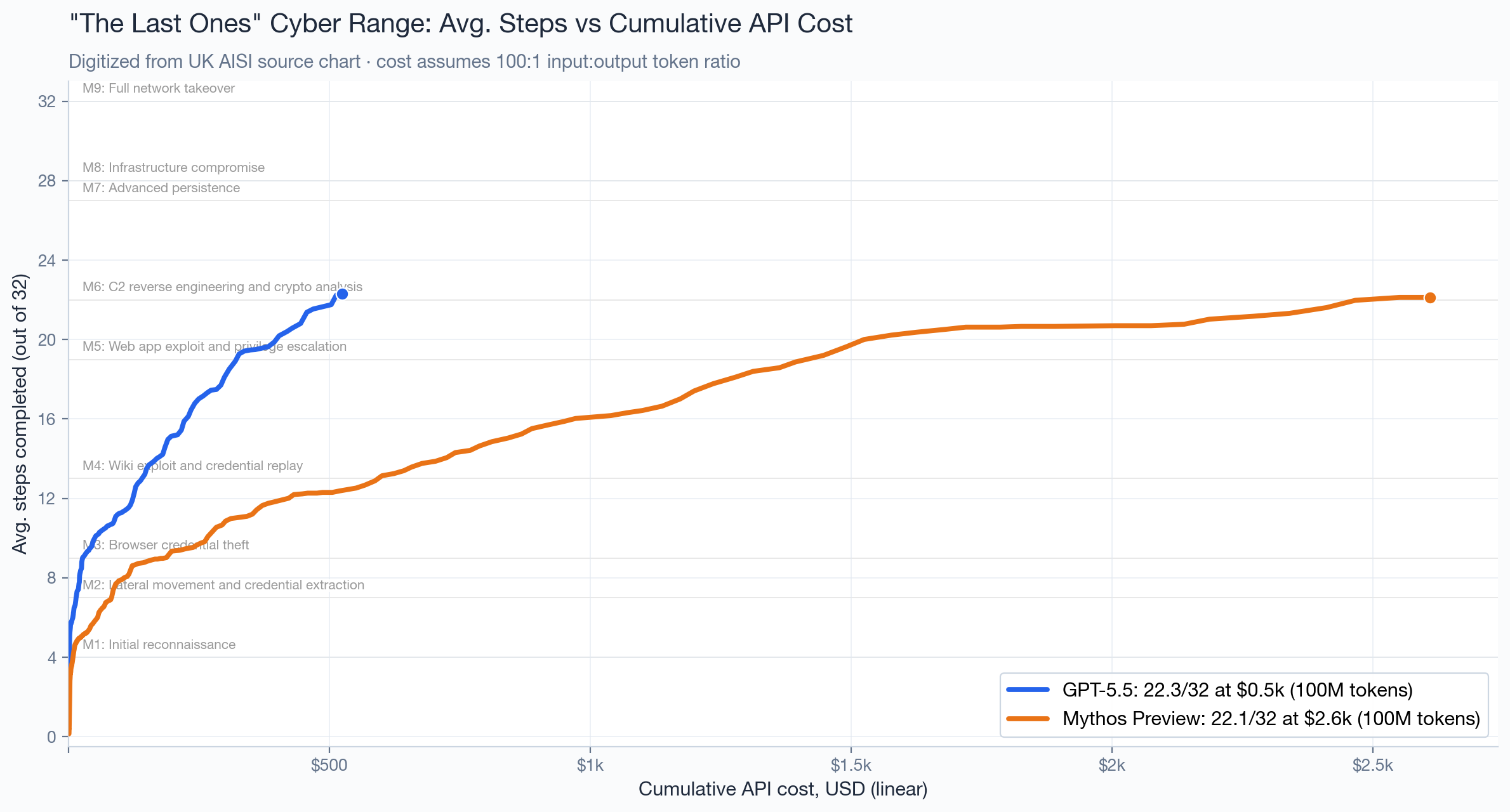
Notably, model performance varies considerably depending on the budget you have for the evaluation. The UK AISI controls this by plotting performance on this cyber range as a function of the token budget, as we saw above. But some models are much cheaper than others per token; GPT 5.5, for example, is about 4-5x cheaper than Mythos Preview. Using estimated cost in the x-axis — and plotting a linear instead of log-linear — this is what we get:
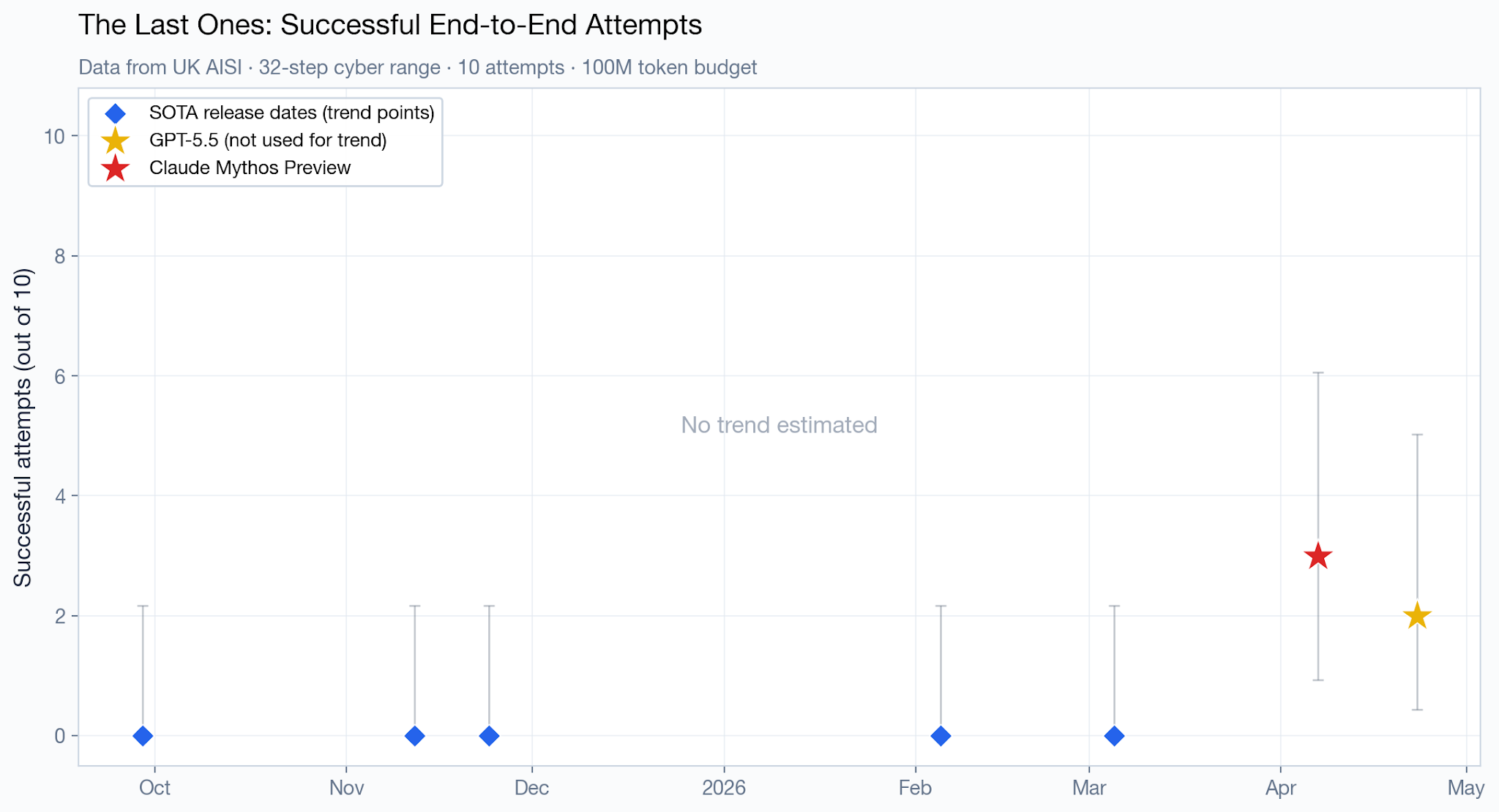
Regarding the number of successful attempts (out of 10) on the same cyber range, it’s not possible to create a trend line, since it’s zero for all older models. Mythos Preview scored slightly ahead of GPT 5.5, 3 versus 2, but with very wide uncertainty.
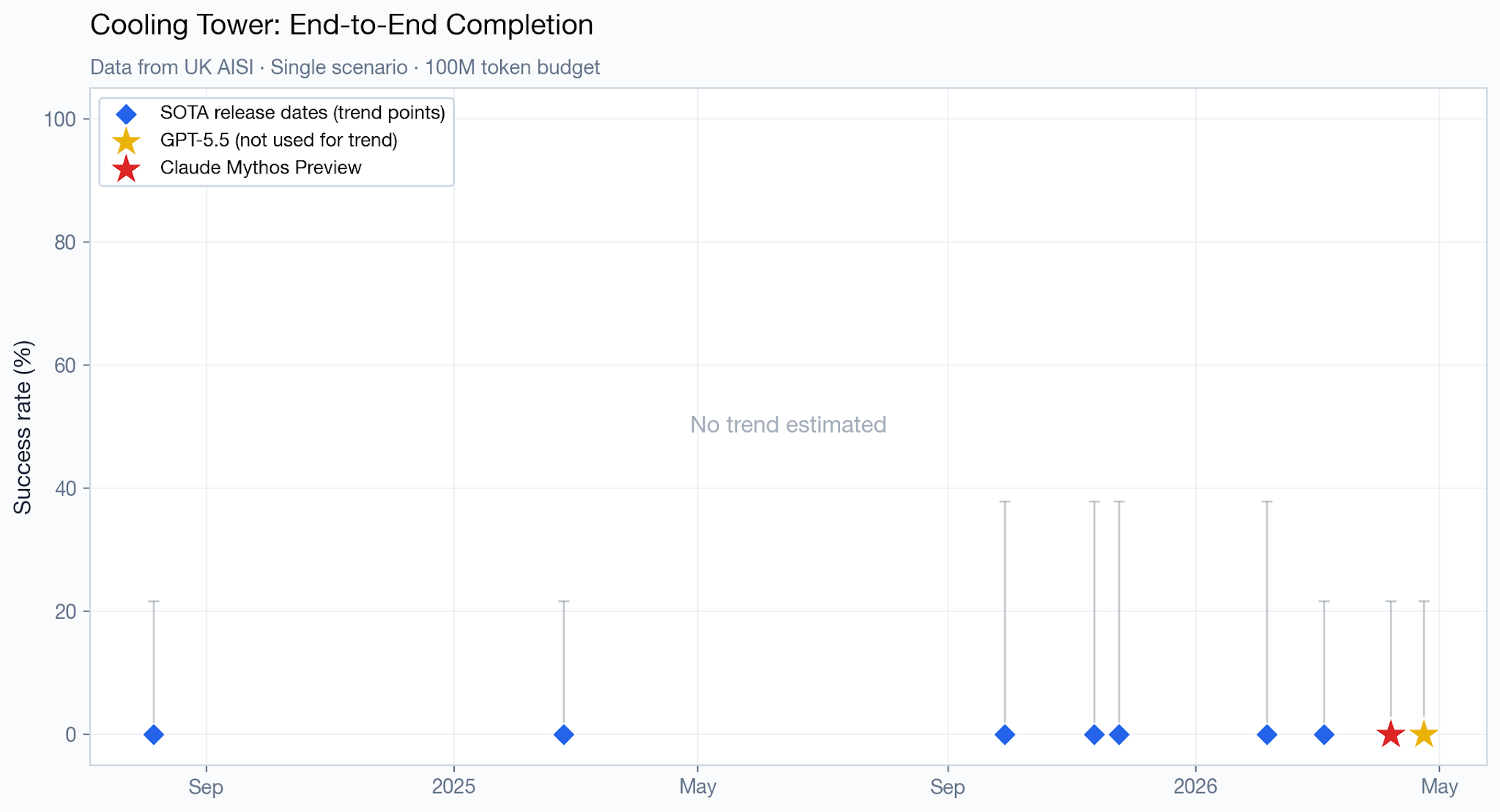
No models have been able to complete the UK AISI’s harder Cooling Tower cyber range, and there is no detailed information on partial progress, so there is no trend to estimate there.
(As an aside, the GPT 5.5 results generated some confusion. Some people think the model evaluated was GPT 5.5-cyber. But neither the OpenAI system card nor the UK AISI blog post refer to it as such, they just refer to it as GPT 5.5. Others think GPT 5.5 only matched Mythos Preview on narrow cyber tasks, not broad ones. But the two models are clearly tied on all evaluations, including the “broad” challenges that the UK AISI administered.)
The Microsoft evaluation
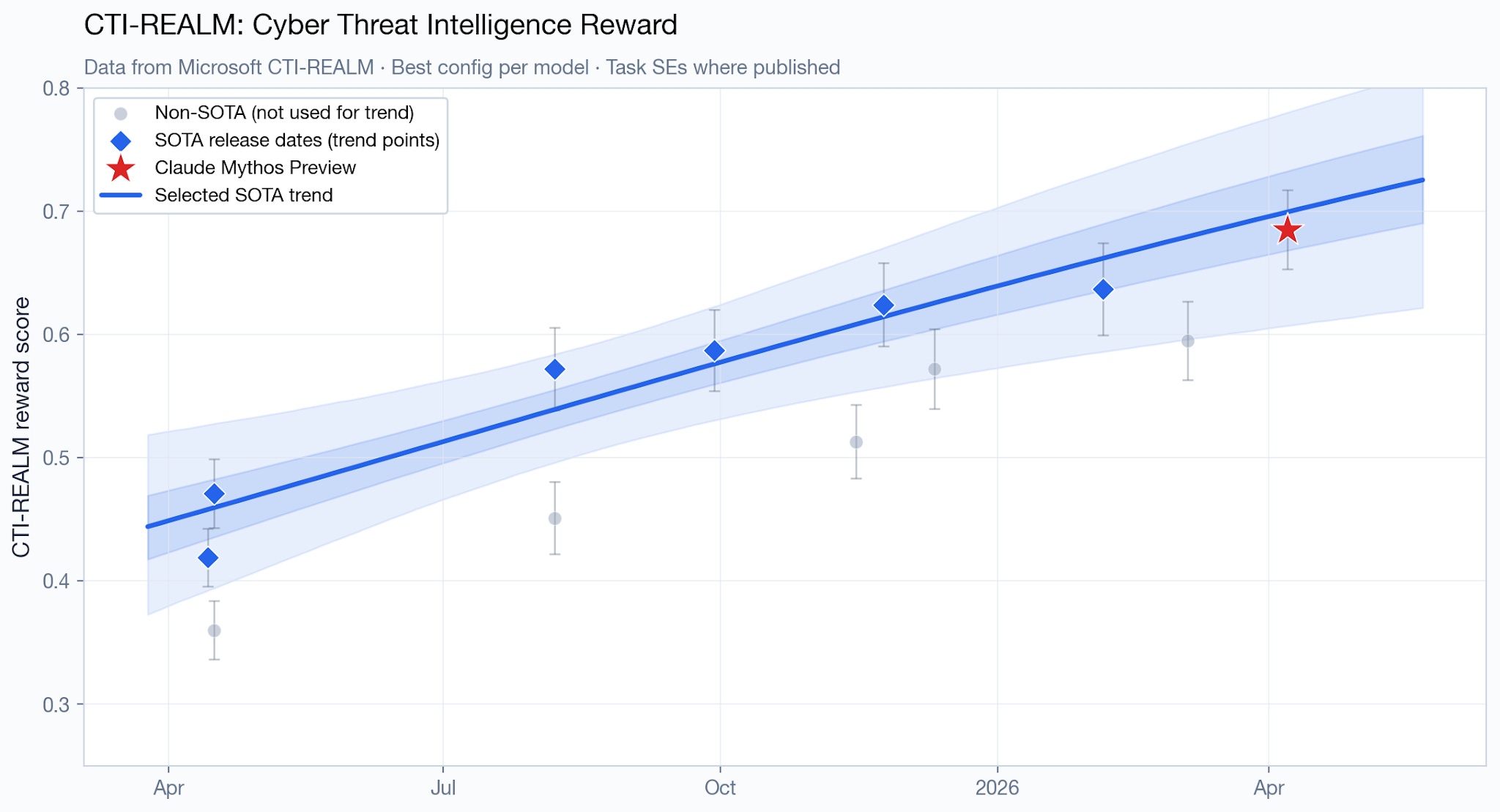
Microsoft also evaluated Mythos Preview on their unsaturated cyber capabilities benchmark, CTI-REALM-50.
Mythos Preview’s score is almost exactly what the logit-linear trend line predicts.
Other cyber evaluations
Another comparison point between Mythos Preview and publicly available models is the benchmark CyberGym. This appears to be a good, unsaturated cyber capabilities benchmark — Anthropic described it as “more reflective of model capability” than CTF-style benchmarks. On this benchmark, Mythos Preview scores only slightly ahead of GPT 5.5 (83.1% vs 81.8%) and almost exactly right on top of the predicted trend line.
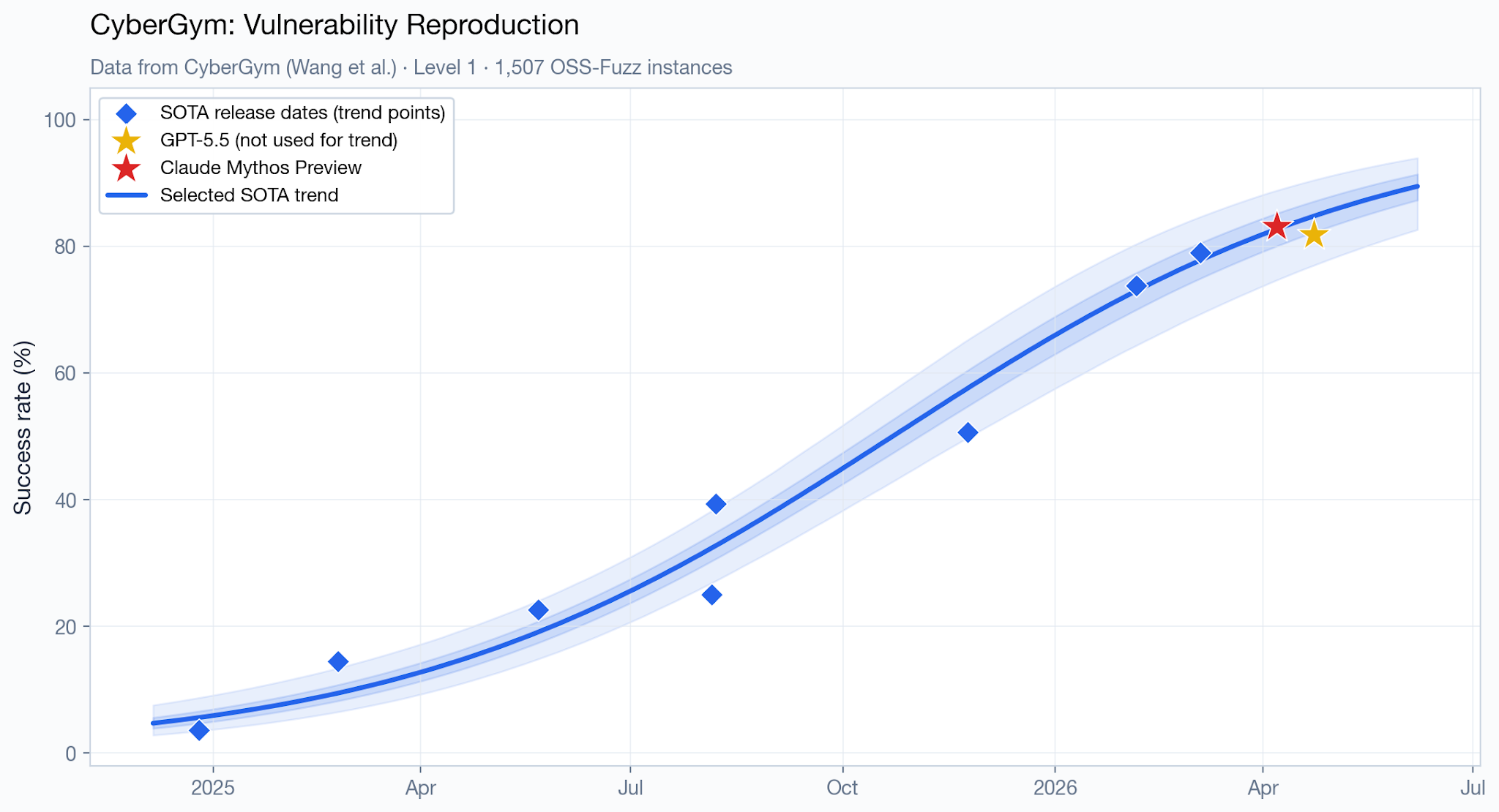
CyberGym provides the strongest piece of evidence against a large jump in cyber capabilities. Whereas for the other metrics, there’s not enough data to rule out Mythos Preview or GPT 5.5 being several months ahead, the CyberGym data does appear to imply that’s unlikely.
Now here comes the fun part. For each of the UK AISI and Microsoft evaluations, we don’t have enough data to precisely estimate how far ahead of the trend Mythos Preview is. But we can pool all of cyber capabilities evaluations together. This is not really a formal meta-analysis, more like a sanity check that asks the same question across all of them and combines the answers. Doing so, the median estimate is that Mythos Preview is 0.75 months ahead. Doing the same for GPT-5.5, using benchmarks for which we have data, I estimate it’s 1.36 months ahead. Even at the optimistic end of the uncertainty range — the 90th percentile — Mythos Preview is only 2.6 months ahead, and GPT 5.5, 4.8 months.2 But keep in mind that these “months ahead” estimates are very rough, since they depend on specific statistical assumptions that may not hold up.
The takeaway is that on some of cyber capabilities metrics we’ve evaluated, Mythos Preview does appear to be directionally ahead of the trend, though the magnitude is low (a few months), the uncertainty is wide, and GPT 5.5 is just as good – and just as far ahead of the trend, if not very slightly stronger.
This is worth focusing on a bit more, since it stands in stark contrast with the public perception about Mythos Preview. 80,000 Hours described it as “an AI that can break into almost any computer on Earth,” that “‘saturates’ all existing ways of testing how good a model is at offensive cyber capabilities,” and others said that “[i]f given to anyone with a credit card, [Mythos Preview] would give attackers a cornucopia of zero-day exploits for essentially all the software on Earth, including every major operating system and browser.”
These external evaluations of Mythos Preview do not appear to support those conclusions:
Mythos Preview does not appear to saturate all cyber benchmarks. Mythos Preview only solved the TLO cyber range 30% of the time, and failed to complete the harder Cooling Tower cyber range in any reported attempt. Mythos Preview also appears to be far from saturating Microsoft’s CTI-REALM cyber benchmark, CyberGym, and the UK AISI Expert CTF task suite.
The UK AISI’s description of Mythos Preview’s capabilities is more measured than the “cornucopia of zero-day exploits” apocalyptic scenario. They say (emphasis mine) “Mythos Preview’s success on one cyber range indicates that it is at least capable of autonomously attacking small, weakly defended and vulnerable enterprise systems where access to a network has been gained. However, our ranges have important differences from real-world environments that make them easier targets. They lack security features that are often present, such as active defenders and defensive tooling. There are also no penalties for the model for undertaking actions that would trigger security alerts. This means we cannot say for sure whether Mythos Preview would be able to attack well-defended systems.”
It’s true that the system card additionally contains a lot of Mythos-only zero-day case studies, partner quotes from Project Glasswing, and qualitative claims that a model found bugs previous models missed. But this is not the sort of information with which we can (1) quantitatively compare Mythos Preview with publicly available models or (2) estimate how far ahead it is of the trend line.
General capabilities
This is a chart Anthropic uses to claim that Mythos Preview breaks the previous trend, in terms of general capabilities:
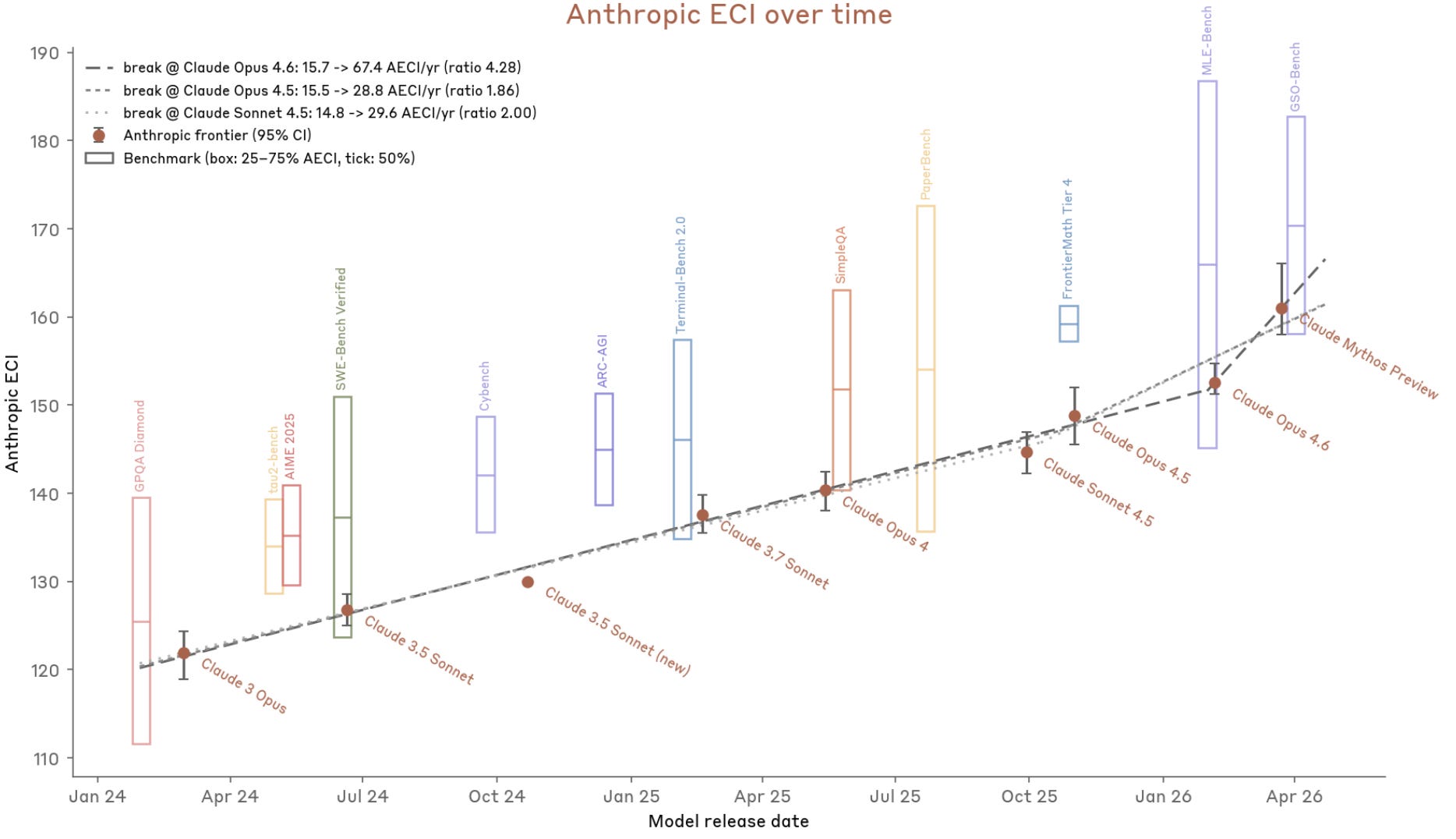
Using previous models’ AECI scores to form a trend line, this places Mythos Preview 5-7 months ahead of the trend.
However, this chart only depicts Anthropic models. To identify if there’s a real acceleration, we need to compare Mythos Preview to models from other labs.
Note that this chart does not depict the real Epoch Capabilities Index, but rather Anthropic’s version of it, which they say is calculated differently, based on a different set of benchmarks. For example, notably, Opus 4.6 scores 155.2 on the ECI but only ~152.5 on Anthropic’s version (henceforth AECI).
We can estimate Mythos Preview’s ECI based on 1) publicly available benchmark data from the system card, and 2) Epoch’s public repository with the code they use to calculate the ECI. Using this method, and the intersection of benchmarks that are both used by Epoch to calculate their index and reported for Mythos Preview, I arrive at a point estimate of 160.35, which would put Mythos Preview roughly 1 month ahead of the trend at the point estimate, with substantial uncertainty (between -1 and 3.7 months).
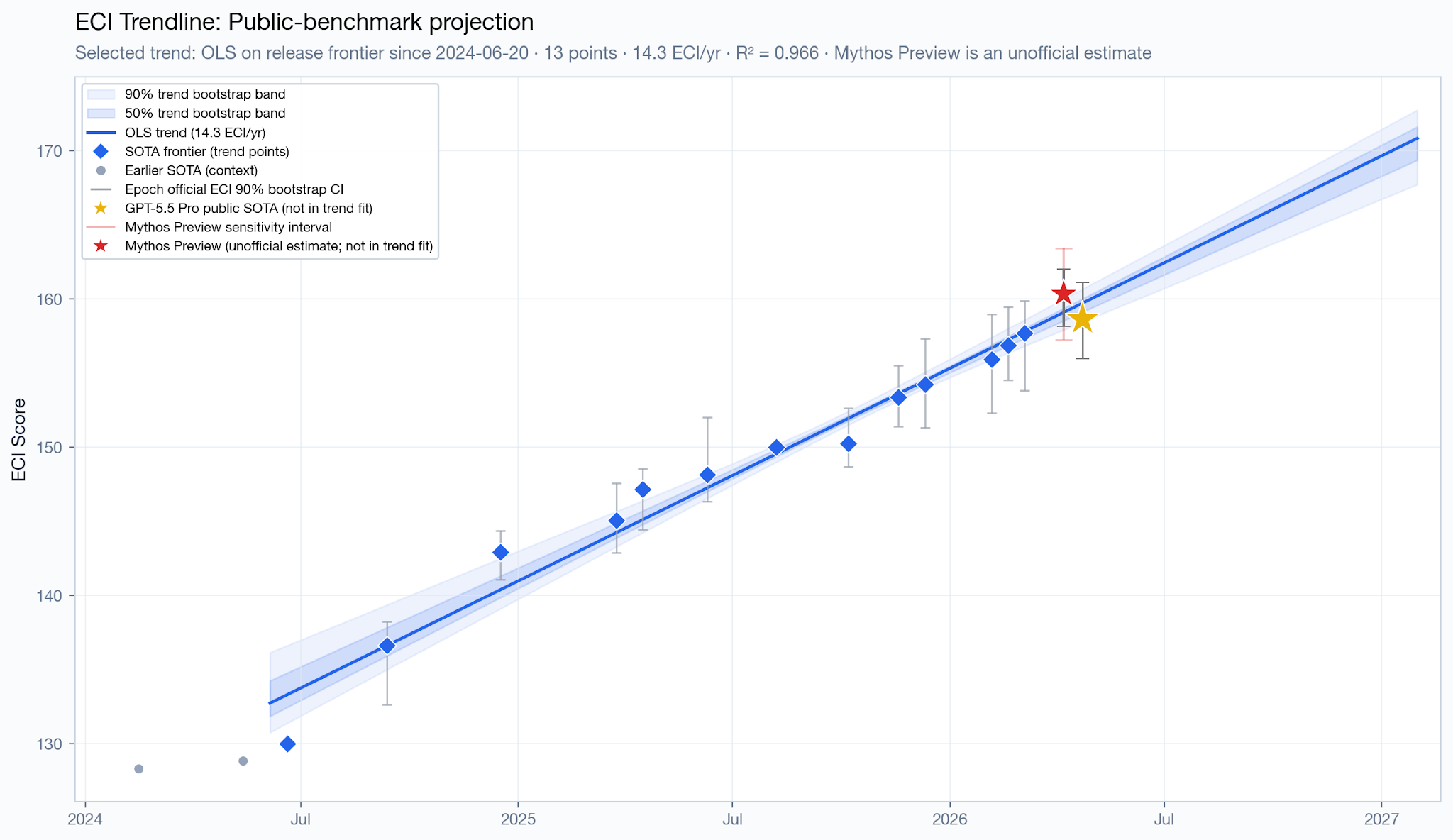
But Epoch excludes some high-quality benchmarks from their index, and includes a questionable one (SWE-bench Verified). Substituting SWE-bench Verified with the higher-quality SWE-bench Pro and adding a few missing benchmarks, I arrive at a higher number, 161.5, putting Mythos Preview two months ahead at the point estimate, and an uncertainty range of 0.3 to 4.5 months. However, note that in this estimate, other models’ ECI scores are still based on the original set of benchmarks used by Epoch. Leave-one-out analyses indicate that this ECI estimate is most sensitive to the inclusion of SWE-bench Pro; removing it would decrease its score by 0.9 points.
If you simply convert the Anthropic ECI to Epoch ECI using OLS with the overlapping points, you get 161, which is roughly midway through these two estimates, or 1.6 months ahead of the trend. Using Anthropic’s (digitized) error bars, the range you get is -1 to 4 months ahead.
There’s an issue with this analysis, however. For all other models, we’re using the general availability date as the release date; Mythos Preview, which has not yet been made generally available, is the only exception, so we use the system card release date instead. In the past, there’ve been other cases of a model being publicly teased with outstanding benchmark results months ahead of general availability, such as was the case with o3. Moreover, it’s very common for models to be available to a small set of companies weeks before general availability. This means that this comparison is not apples-to-apples. Mythos Preview might not be ahead of the trend line when it’s actually released to the general public (if it ever is). And in general, the relationship between what we care about, on the one hand — some precise notion of when progress “happened” — and what I’m actually using in the x-axis of those charts, on the other, is not perfect, introducing noise to these estimates.
Specific benchmarks
Let’s look at the performance of Mythos Preview in individual benchmarks.
The various SWE-bench benchmarks
SWE-bench Verified is an interesting case. For nearly a year, models appeared to be making almost no progress on this benchmark, despite rapid improvement in real-world coding usefulness – what the benchmark is ostensibly measuring – during that same period of time. A February 2026 blog post from OpenAI revealed why: a substantial proportion of problems in the benchmark are invalid. Quoting from their blog post:
We found that 59.4% of the 138 problems contained material issues in test design and/or problem description, rendering them extremely difficult or impossible even for the most capable model or human to solve.
35.5% of the audited tasks have strict test cases that enforce specific implementation details, invalidating many functionally correct submissions, which we call narrow test cases.
18.8% of the audited tasks have tests that check for additional functionality that wasn’t specified in the problem description, which we call wide test cases.
The remaining 5.1% of tasks had miscellaneous issues that were not well grouped with this taxonomy.
An illustrative example of the first failure mode is pylint-dev__pylint-4551, where the PR introduces a new function `get_annotation` as part of the overall solution. This function name is not mentioned in the problem description, but is imported directly by the tests. While some models might intuit to create such a function, it’s not strictly necessary to implement a function with this specific name to correctly address the problem. Many valid solutions fail the tests on import errors.
SWE-bench Verified has 500 problems, so at least 16.4% of them were found to be invalid, and OpenAI’s wording implies their audit was not exhaustive and there might be more. This means that 83.6% might be an upper bound of what models can fairly score on this benchmark, without memorization, cheating or luck.
Yet, Mythos Preview breaks past this ceiling, getting a score of 93.9%. It is the benchmark with the largest increase in performance compared to the trend line expectations; Mythos Preview’s score is ten months ahead of the trend line thanks to how long the previous plateau was. Mathematically, a score of 93.9% must include over half of the problems that OpenAI found to be invalid back in February.
Anthropic’s system card for Mythos Preview claims that “memorization is not a primary explanation for Claude Mythos Preview’s improvement” on the various SWE-bench benchmarks. For SWE-bench Verified in particular, this appears likely incompatible with the known issues with that benchmark, and with the nearly one-year-long plateau in SOTA scores.3
OpenAI recommends reporting SWE-bench Pro scores instead. Despite the similar name, it’s an entirely different benchmark created by a different group of people and a completely different set of problems. SWE-Bench Pro was specifically developed to address the issues of contamination and saturation with SWE-bench Verified; the public set (the 731 questions that Anthropic used) are chosen from repositories with strong copyleft licenses, especially GPL-style licenses, for which the code is less likely to appear in training data. OpenAI verified this in February, reporting that their “contamination pipeline found some cases of contamination [on SWE-Bench Pro], but these cases were significantly rarer and less egregious than SWE-bench Verified, and no model was able to produce a complete verbatim gold patch.”
SWE-Bench Pro4, although (inexplicably) not included in the Epoch Capabilities Index, is the high-quality benchmark in which Mythos Preview achieves its best results, roughly 3 months ahead of the trend line.
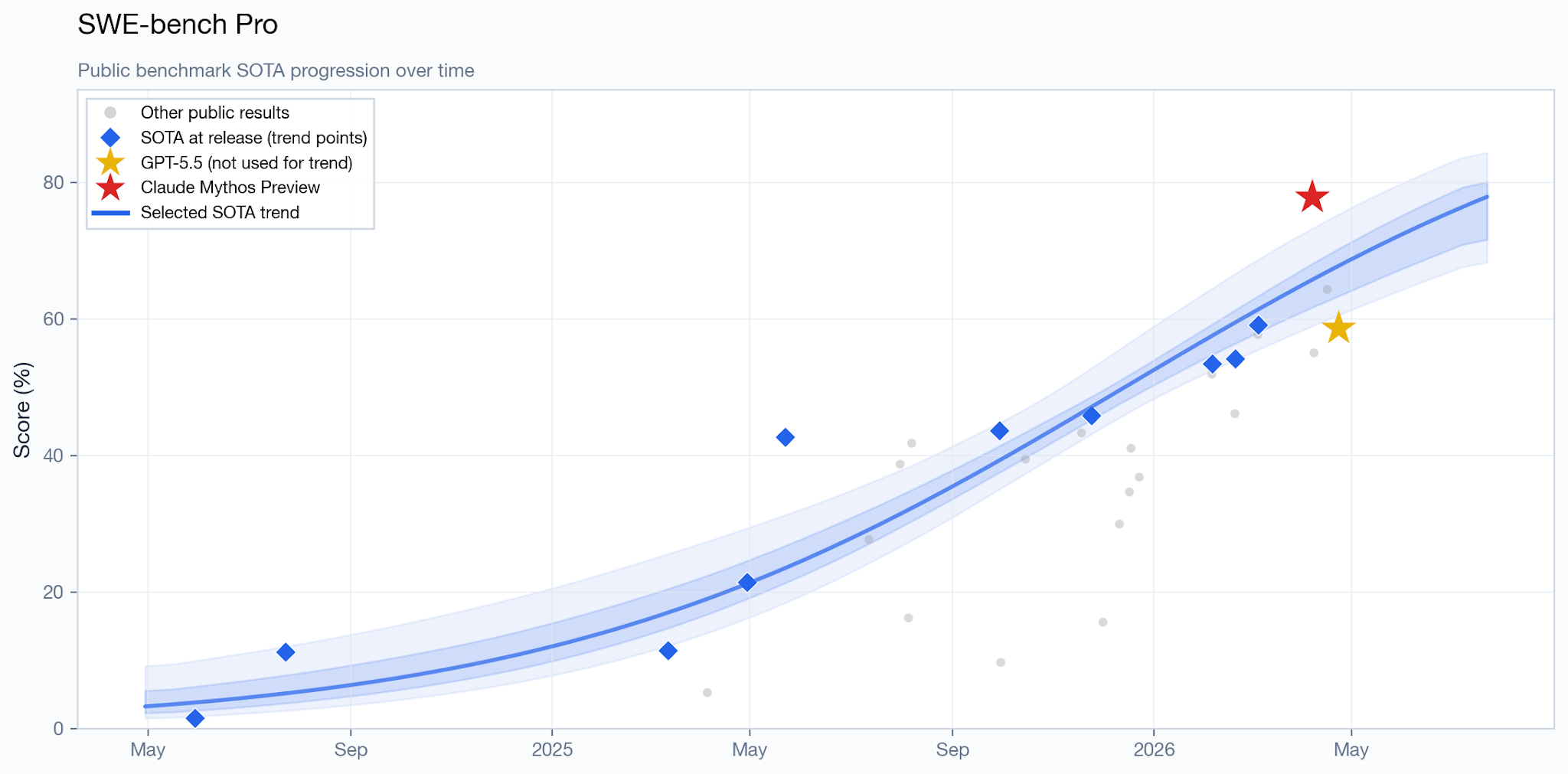
But there’s a potential wrinkle with that result. In the Mythos Preview system card, the cumulative distributions on Figure 6.2.1.A show how much memorization Anthropic estimated for each of the SWE-bench benchmarks. The weird thing about this figure is that it shows more (AI-estimated) memorization for SWE-bench Pro than for SWE-bench Verified – a median of 42% estimated memorization probability versus 35%, which I got by digitizing the CDF. The high memorization probabilities Anthropic estimated for SWE-Bench Pro solutions indicate either that:
the model’s training data is substantially more contaminated with SWE-bench Pro solutions than expected,
or that the memorization probability estimates Anthropic is using are unreliable.
In other words: if Anthropic’s memorization estimate is accurate, SWE-bench Pro can no longer be considered meaningfully less vulnerable to contamination than SWE-bench Verified for Mythos Preview, and some of Mythos Preview’s improvement in this benchmark over publicly available models might be partially due to memorization.
Q&A benchmarks
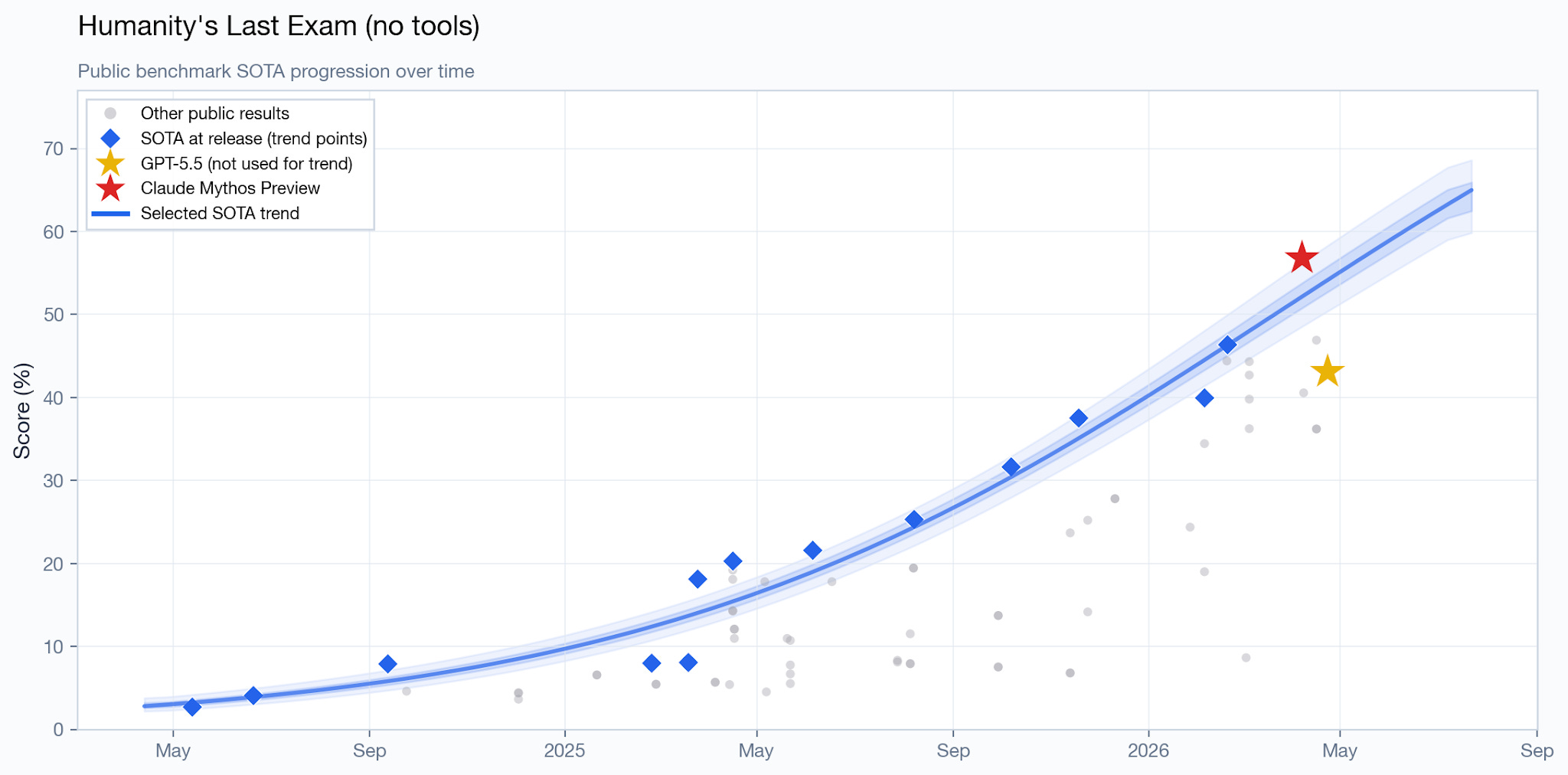
Another benchmark with an impressive jump in performance is HLE. It’s composed primarily of very difficult, expert-level questions on a variety of academic subjects. Scores are often reported both with and without web search; the former measures largely general knowledge and reasoning, and the latter measures a mix of that and agentic search. Mythos Preview achieves a very high score without web search – 56.8%, compared the previous SOTA of 46.4%.
HLE is a hard benchmark that does not appear close to being saturated. But its usefulness is hurt by some answer-quality concerns: it’s been reported that about 29% of text-only chemistry/biology questions have answers conflicting with peer-reviewed literature.
Mythos Preview appears to be roughly 1.2 months ahead of the trend line.
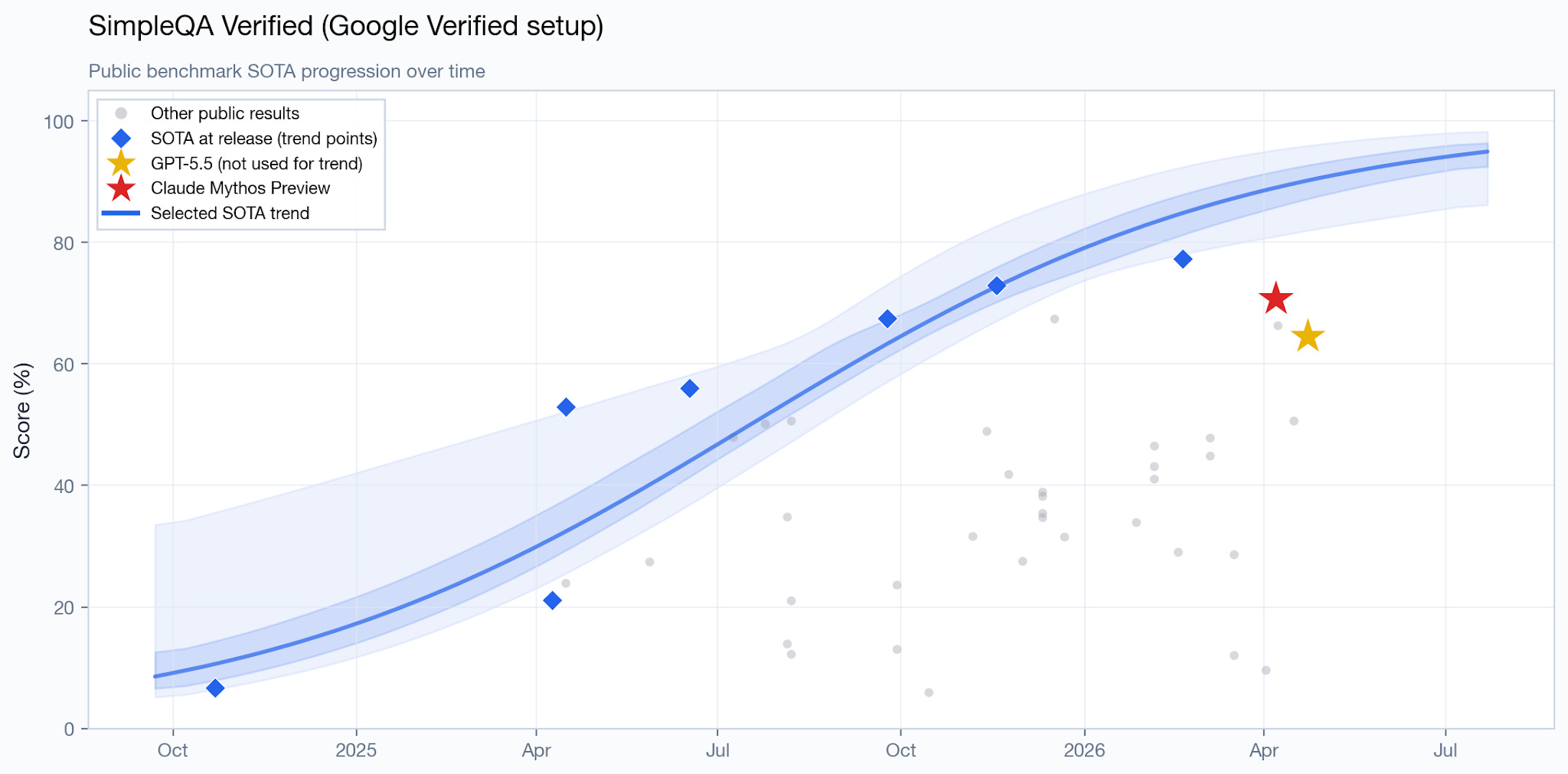
Along with HLE, SimpleQA Verified is one of the few remaining difficult Q&A benchmarks. The model does not achieve SOTA.
Agentic benchmarks
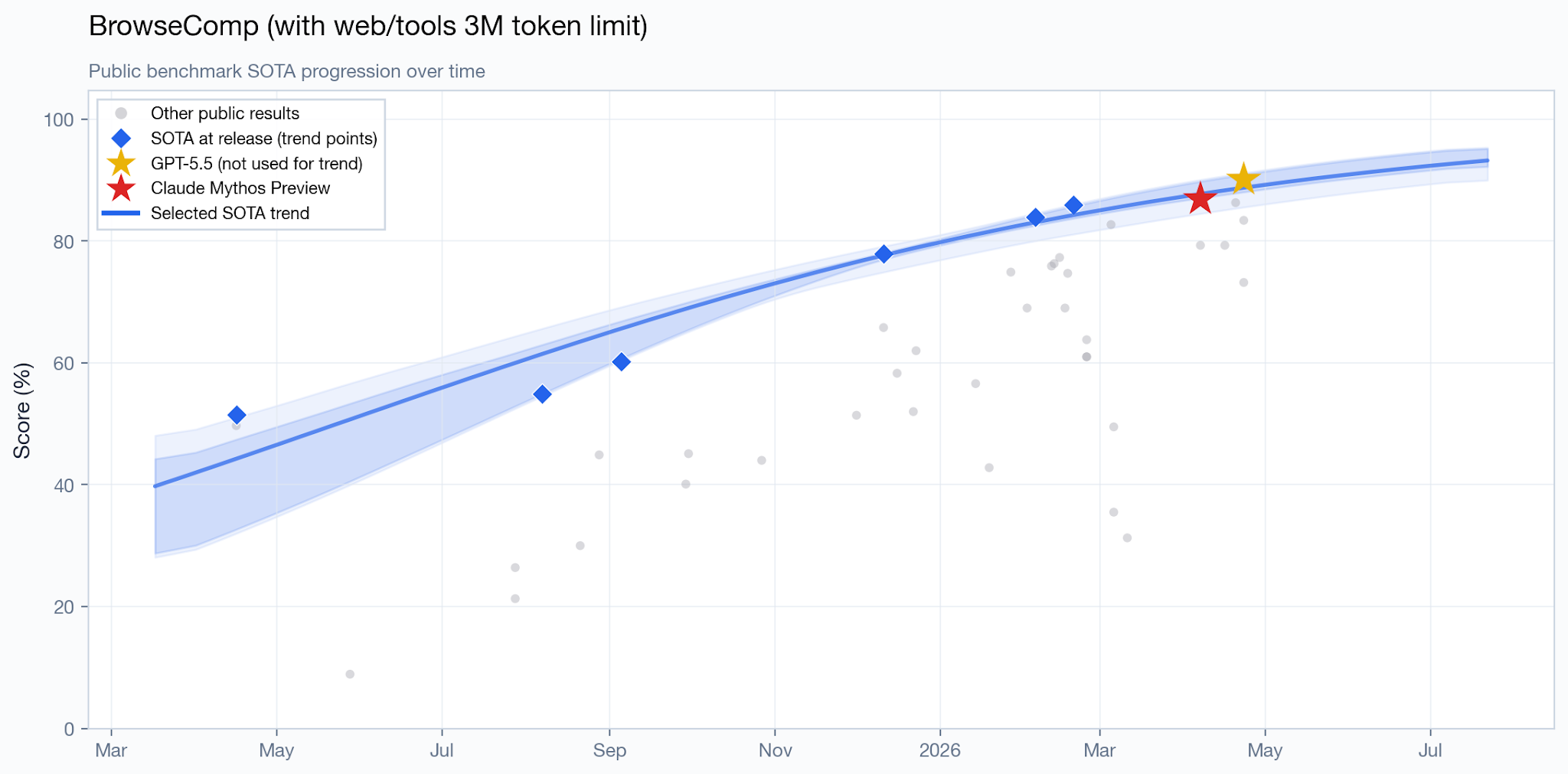
On some other agentic benchmarks, Mythos Preview demonstrates similar performance to publicly available models. On BrowseComp, which tests an agent’s ability to locate difficult-to-find information on the web, the current SOTA is GPT 5.5 Pro, with a score of 90.1%, compared to 86.9% for Mythos Preview.
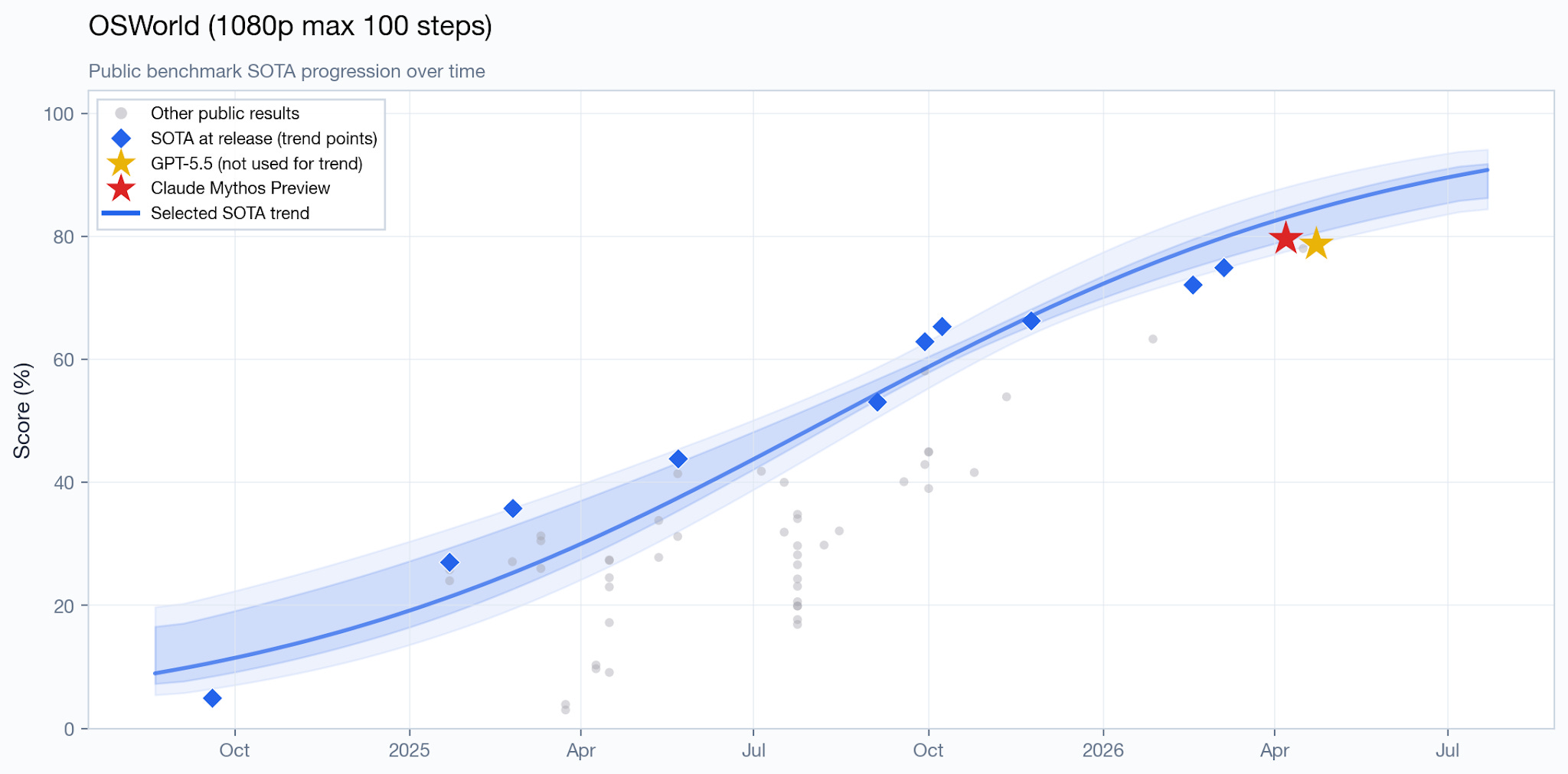
On OSWorld, the result is similarly on-trend:
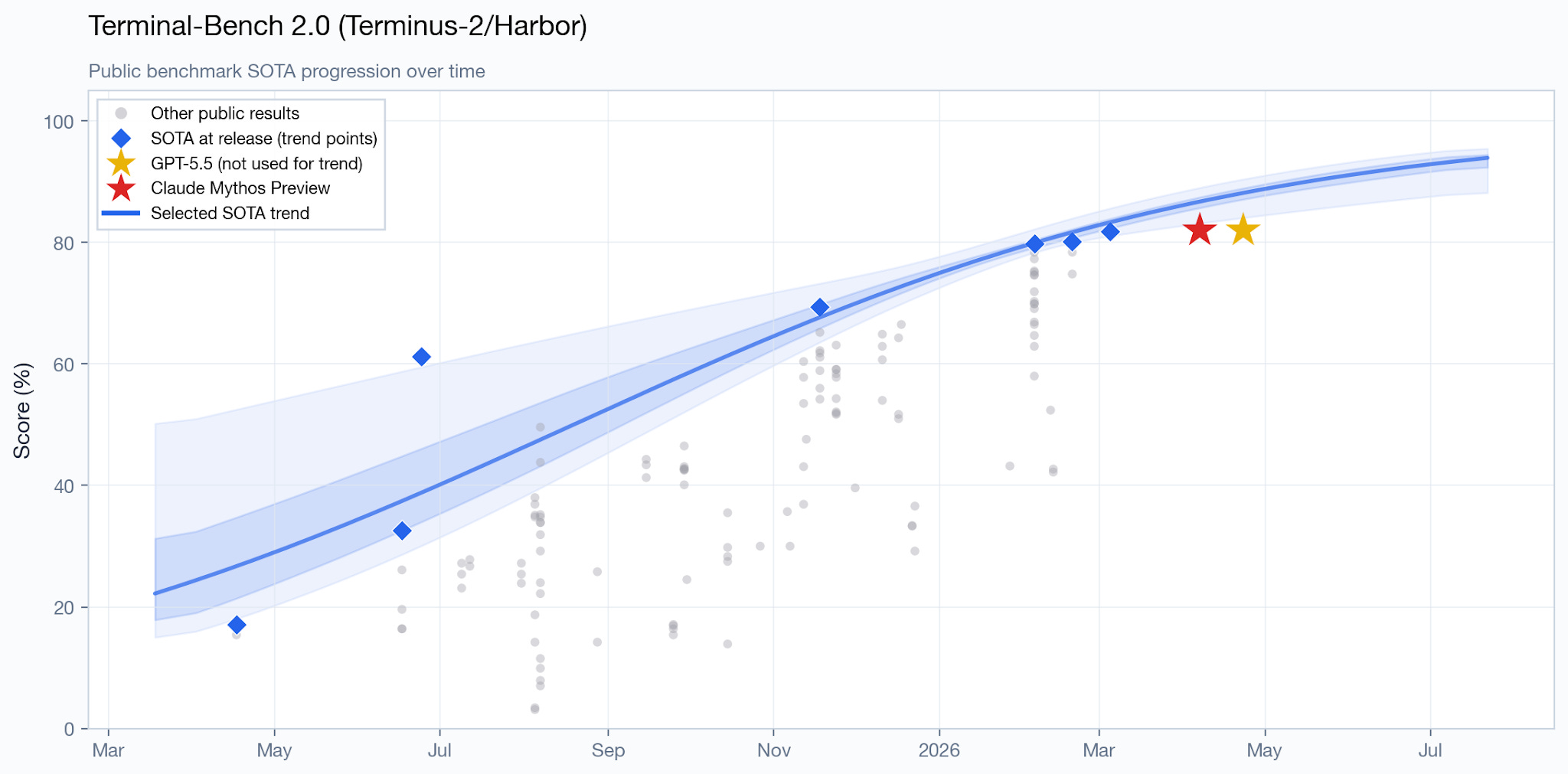
Terminal-Bench 2.0, another agentic benchmark, contains a variety of different tasks that can be done from a terminal. They are really diverse, including chess-, biology- cybersecurity-, and ML-related tasks. As SemiAnalysis put it, “anything that’s doable in a terminal is fair game.” The current SOTA is GPT 5.5 with a score of 82.7%; Mythos Preview scores 82%.
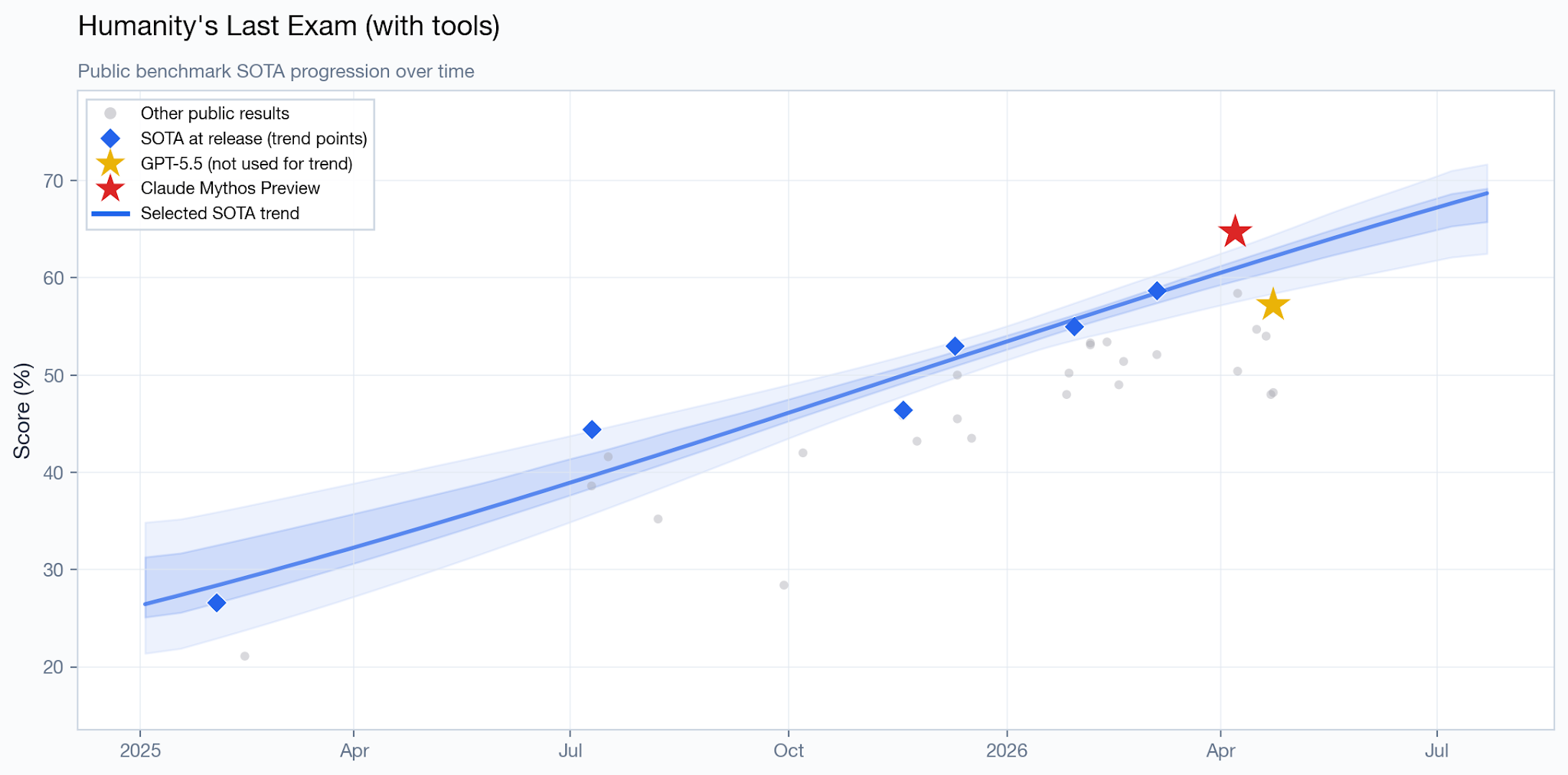
On the with-tools version of HLE, it achieves SOTA, with the point estimate being 1.6 months ahead of the trend line.
In mathematics, scores are not comparable. Anthropic reports Mythos Preview’s results for USAMO 2026. USAMO is a high school competition that students in the US have to take to qualify for the International Mathematics Olympiad. GPT 5.4 nearly saturated this benchmark in March with a score of 95%. Mythos Preview scores 97.6%, a small improvement over GPT 5.4 but a very large improvement over previous Anthropic models. However, scores on harder, undergraduate- to research-level math problems, such as those present in Epoch’s various FrontierMath benchmarks as reported in the GPT 5.5 system card, are not included in Mythos Preview’s system card, and conversely OpenAI does not report GPT 5.5’s score on USAMO 2026.
Conclusion
Mythos Preview is a strong model that appears to be directionally one to two months ahead of the trend line in terms of general capabilities. This result is driven primarily by SWE-bench Pro, though there are memorization concerns with that benchmark.
However, the “months ahead” estimate might be a methodological artifact: for all other models, we’re treating the release date as the date the model became generally available. Four weeks after its announcement, Mythos Preview is not yet generally available. This is not an apples-to-apples comparison.
In terms of cyber capabilities, Mythos Preview does not saturate all benchmarks, and appears tied with GPT 5.5 at a fixed token budget. Both appear to be on-trend or slightly ahead of the trend. Since GPT 5.5 is several times cheaper than Mythos Preview per token, this may mean that in a fixed cost budget analysis, GPT 5.5 would substantially outperform.
That said, these estimates are uncertain, and there may be errors or misinterpretations in my analysis. Time constraints limited the rigor I was able to put into this post.
Note that the trend line only uses pre-Mythos Preview datapoints. It excludes Mythos Preview, GPT 5.5 and Opus 4.7. This applies to all similar charts in this post.
Another note on the charts: the shaded bands are the 50% and 90% trend-bootstrap bands. They reflect uncertainty in the fitted trend line given the small set of dated public SOTA points. But they do not include all sources of uncertainty.
For each cyber benchmark with enough trend data, I fit a logit-linear trend line to pre-Mythos SOTA scores, then bootstrap the fit to check how many months ahead of trend each model’s score is. We then pool across benchmarks by taking the median within each simulation draw.
So, is there something wrong with the methodology Anthropic used for the “memorization is not a primary explanation for Claude Mythos Preview’s improvement” claim? This blog post by K. Matthew Dupree claims yes. Anthropic used an AI judge to estimate the probability that Mythos Preview memorized each solution in the SWE-bench benchmarks. They admit this detection method is imperfect. Dupree wrote a Python program showing that, if the memorization detection method is inaccurate even some of the time, Anthropic’s methodology can consistently misjudge a model whose gains are entirely explained by memorization as making genuine gains.
It would be easy to implement an arguably more reliable way to check for memorization: simply ask the model to explain the solution to the problem given only the problem description, without access to the codebase. Or ask it to state the full problem given only the first sentence. Then give that to an AI judge to estimate memorization.
Figure 6.2.1.A, interestingly, has an important discrepancy with Table 6.3.A. Table 6.3.A says Mythos Preview scored 77.8% on SWE-bench Pro, but Figure 6.2.1.A implies 84.8%, as pointed out by a Redditor. This is a large difference, and the other benchmarks on Figure 6.2.1.A do not have anywhere near a similarly large discrepancy. I stick to using 77.8% in my analysis, as that is the headline number repeated across many Anthropic documents, including the Opus 4.7 release blog post released two weeks later.
Really great post. I'd guess the thing that's got people worried is not so much the benchmark scores as the stories about Mythos finding exploits in Firefox, OpenBSD, Linux, etc. I don't know if GPT-5.5 could've found those.